Rethinking Data Lifelines in the Age of RAG and MCPs
Rethinking Data Lifelines in the Age of RAG and MCPs
Imagine supervising a wind farm with hundreds of turbines. Each one has its own history, whether it's maintenance, weather events, or parts wear. Now imagine asking your AI agent:
"Why did Turbine 173 spike in temperature and drop efficiency last night?"
If your data pipeline relies on traditional DataOps ETL/ELT processes, that agent may have no idea. The trail—the data lifeline—has already been transformed, aggregated, or discarded.
Post-Mortem Context: When Data Dies Too Early
Traditional DataOps, built on ETL/ELT processes are here to extract, transform, and load data into structures to prepare it for human analysis. They clean, shape, and aggregate vast amounts of information into neat, structured reports.
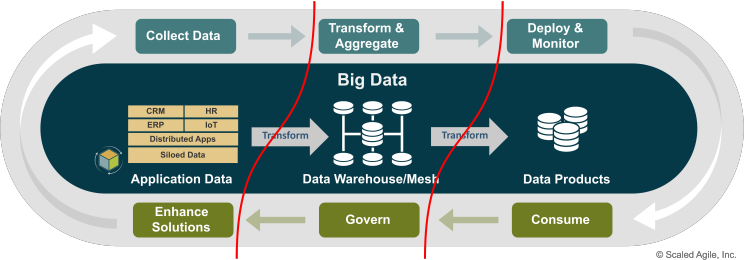
But here's the problem: Once data is transformed no longer alive - its lifeline is cut.
- The temporal fidelity is lost—the exact sequence of events is blurred into averages.
- The semantic context is flattened—the rich relationships between data points are erased.
- The causal clues—the very information needed to understand why something happened is gone.
For intelligent agents, this results in post-mortem context: data that’s already been autopsied before AI can reason about it.
The High Cost of Cold Cases
This isn't just a technical problem; it's a business problem. When an AI agent can't access live, contextual data, the consequences are significant:
- Delayed Reactions: Instead of predicting a failure, you're reacting to it. The lag between an event and its analysis can lead to extended downtime and costly repairs.
- Flawed Decisions: An agent operating on summarized data might recommend a generic solution that misses the specific cause, leading to ineffective maintenance and recurring issues.
- Missed Opportunities: Without the full picture, you can't spot subtle patterns of inefficiency or opportunities for optimization across your assets. The "messy" data often holds the most valuable insights.
Agents Need Access to Real-World, Real-Time Signals
Modern AI agents, especially those using Retrieval-Augmented Generation (RAG) within Model Context Protocols (MCPs), don't want summaries. They need to tap into the raw, messy, truthful stream of what actually happened: real-time sensor telemetry, unfiltered logs and event streams, maintenance actions and fault records, dynamic environmental conditions...
This is the lifeblood of autonomous reasoning. It enables RAG (Retrieval-Augmented Generation) systems to ground their answers in real data—not in hallucinated summaries.
In our wind turbine example, The agent shouldn’t be reading a cleaned KPI table. It should be querying a knowledge graph that reflects the asset’s full operational timeline.
Replace Data Pipelines with Semantic Context Layers
To support AI-driven operations, we need infrastructure designed for machine-native consumption:
From pipelines → to event-native architectures enabling cognition:
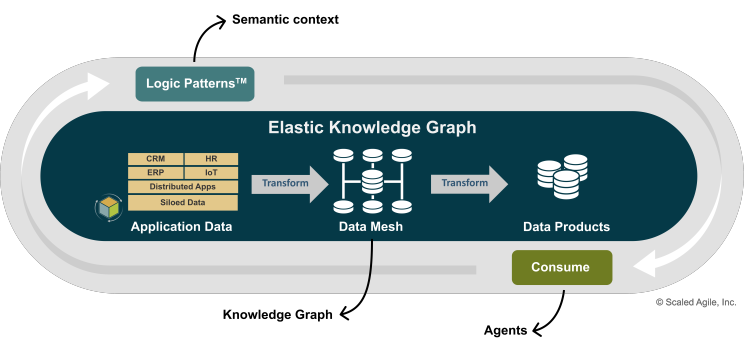
- Data Mesh Architectures: A Data Mesh decentralizes data ownership, treating data as a product. This preserves the rich, local signals from their original source, preventing premature aggregation by a central pipeline. Each domain (e.g., operations, maintenance) exposes its data in a ready-to-use, machine-readable format.
- Knowledge Graphs: While a Data Mesh provides the data, a Knowledge Graph encodes the meaning. It maps the deep semantic relationships between entities—connecting Turbine 173 to its specific sensors, the last maintenance log, and the weather conditions at the time of the event. This is the brain that allows the AI to understand the context.
- RAG-Ready Interfaces: These are the doorways for the AI. They allow an agent to "ask" complex questions and retrieve precise, just-in-time information from the Knowledge Graph and Data Mesh, getting the exact data it needs to reason, without having to sift through a dead, pre-processed database.
- Direct Sensing access that maintains a live view of asset behavior.
In short: we need to keep data alive.
Solving the Case: The Wind Turbine Revisited
Let's return to our initial question and see the difference this new architecture makes.
Scenario 1: The Old Way (ETL/ELT) You ask: "Why did Turbine 173 spike in temperature and drop in efficiency?" The agent queries a data warehouse. The data has been aggregated into hourly averages. The agent replies: "Last night, Turbine 173's average temperature was 15% above normal, and its efficiency dropped by 8%." This is a report, not an answer. It tells you what happened, but not why. The trail is cold.
Scenario 2: The New Way (Cognitive Layer) You ask the same question.
- The RAG-Ready Interface translates your question into a query for the Knowledge Graph.
- The Knowledge Graph identifies "Turbine 173" and its related events. It sees the temperature spike from a specific sensor and correlates it in time with the efficiency drop.
- It traverses further, finding a maintenance log from the previous day noting a "coolant sensor replacement." It also pulls real-time weather data from the Data Mesh, ruling out external factors.
- The agent synthesizes this information and replies: "The temperature spike on Turbine 173 was caused by a malfunctioning coolant sensor, model X, which was installed yesterday. This is causing the efficiency drop. I have already scheduled a technician to inspect it and cross-referenced this failure with other turbines using the same sensor batch."
This is a true, autonomous investigation. The agent didn't just read data; it reasoned over it.
A Philosophical Shift in DataOps
ETL/ELT assumes data is for humans. But in a world of AI agents, data must speak to machines.
“Summarized data is the corpse. What the agents need is the heartbeat.”
Final Thought
If you want your agents to operate with genuine intelligence, they must be able to think in real-time, reason through the "messy middle," and remember what really happened. The goal is no longer just to store data, but to keep it alive, connected, and ready for inquiry.
Don’t kill the data too early. Keep the lifeline intact—and let your machines think.
